|
Research Stage 1 — Easy!
In observing graphs of this sort, I conjectured that other typists would probably not be slow in exactly the same locations that I was slow, and would not be fast in exactly the same locations that I was fast, and that the graph presents my own unique profile of typing behavior for the given sentence. Indeed, when I compared my profile to that of others, clear and consistent differences were evident. The possibility suggested itself, therefore, that some invisible and anonymous person typing at some distant keyboard might be identifiable from the pattern of time intervals between keystrokes. A program that I wrote was able to identify the typists of a selection of sentences with 100% accuracy.
This work proceeded on to two further stages.
Research Stage 2 — Not too hard!
The second stage addressed the question of whether it was possible to identify a keyboard user when a sample of his typing had been previously obtained, but when at the moment he was typing not some standard sentence that he had typed before, but something quite new. The programming challenge was greater at this second stage, and was aided by a closer scrutiny of keyboard dynamics — not only was the time at which each key was depressed noted, but the time at which each key was released (which might be called the KeyDOWN and KeyUP events), and also too the KeyDOWN and KeyUP events for the Shift and Enter keys were recorded. The value of these more detailed observations might be appreciated by noting that in typing a capital N, the sequence of keystrokes might be Shift-DOWN, N-DOWN, N-UP, Shift-UP, but might also be Shift-DOWN, N-DOWN, Shift-UP, N-UP. The effect on the characters appearing on the computer monitor is identical in these alternative cases, and considerable such idiosyncrasies are able to develop and will be detected only by means of such very accurate measurements as are made possible by the computer. The appearance of one pattern or the other in the lifting of the Shift key, then, is an example of the sort of clue that may aid in indicating who it is that is sitting at a keyboard, as is more generally the staccato-legato pattern of keystroke depression that becomes measurable with the recording of the times of both the KeyDOWN and KeyUP events.
In this second stage of the project, too, conquest was not terribly difficult — it was possible to identify who was at the keyboard even when that person was typing something new. However, I did not pause long at this second stage of the research because I was drawn on by the possibility of a comparably-easy conquest at the third stage, which was the most exciting of the three.
What happened after the conquest of the second stage was that I turned to see what was available in the literature on the subject, and found, as I had expected, that work had been done. My brief glance at the literature did not tell me whether anybody was achieving accurate keyboard-user identifications for new text as I was, but certainly the idea had been thought of, and the general approach had been discussed, and preliminary work had been published. One firm offers a system which verifies that the person typing a password is really the password owner by examining keyboard dynamics, with one wonders what reliability and how many satisfied customers.
Research Stage 3 — Very hard!
My glance at the literature pointed me in the direction of a third level of investigation that the project could be taken to. That is, I read that in some circumstances, a keyboard-user's work might be encrypted, and yet the encrypted characters might be transmitted keystroke by keystroke as they took place, which is to say with inter-keystroke intervals intact. This led me to the supposition that it might be possible to ask an entirely different question than before — not who was typing some known text, but in the case of a known typist transmitting encrypted text, what the corresponding unencrypted text might be.
The third stage of the project, then, could be visualized as being told nothing better than that a sequence of keystrokes consisted of only asterisks, but from the time pattern between those asterisks to infer what was really being typed.
What a preliminary exploration showed here was that the difficulty of the research had risen considerably. Whereas the first two levels were elementary, and yielded up their secrets to the first dozen algorithms tested, this third level of the project showed that useable results were not to be extracted from a brief effort. The time pattern of any sequence of encrypted text did surely contain information that would permit some inferences to be drawn concerning the content, but discovering how best to extract that content might require more than one researcher working on more than a personal computer for more than a few days.
Conclusions
A person sitting at a keyboard who may think that he is typing anonymously, is in fact leaving a distinctive fingerprint which uniquely identifies him — at least he is in situations where his keyboard dynamics can be monitored. As the phenomenon has been under discussion for many years, and as algorithms which permit such identification prove to be elementary, one might take as a certainty that programs which permit such keyboard-user identification have been written and are in use, even if they are not widely discussed or acknowledged. As they are possibly in widest use by security agencies, or institutions which want their use to remain secret, one might expect that the particular algorithms that have proven most effective will not be found in the publicly-accessible literature. If such user-identifying programs are not in use, then our security agencies are more incompetant than I imagined, or — to adopt their point of view — more underfunded.
Furthermore, in cases where keyboard dynamics can be monitored, encryption may offer only limited security, as the keyboard dynamics offer considerable information on the unencrypted text that is being typed. That this has not occurred to security agencies is inconceivable — of course it has occurred to them. That security agencies have not researched the possibility is inconceivable — of course they have researched it. That this line of research has failed to turn up useable results is inconceivable — of course it has turned up useable results. The bottom line, then, is that there is a high probability that encryption can, to some degree, be broken by an examination of keyboard dynamics, and that it is being so broken every day of the year.
Then, too, it is possible to imagine criminal organizations using the same technology to draw inferences concerning charge-card numbers or passwords which are sent encrypted but whose keyboard dynamics are evident. A final line of speculation envisions software which transmits a message employing some given individual's keyboard profile so as to make it appear that he is typing it — a program that can be written in a day.
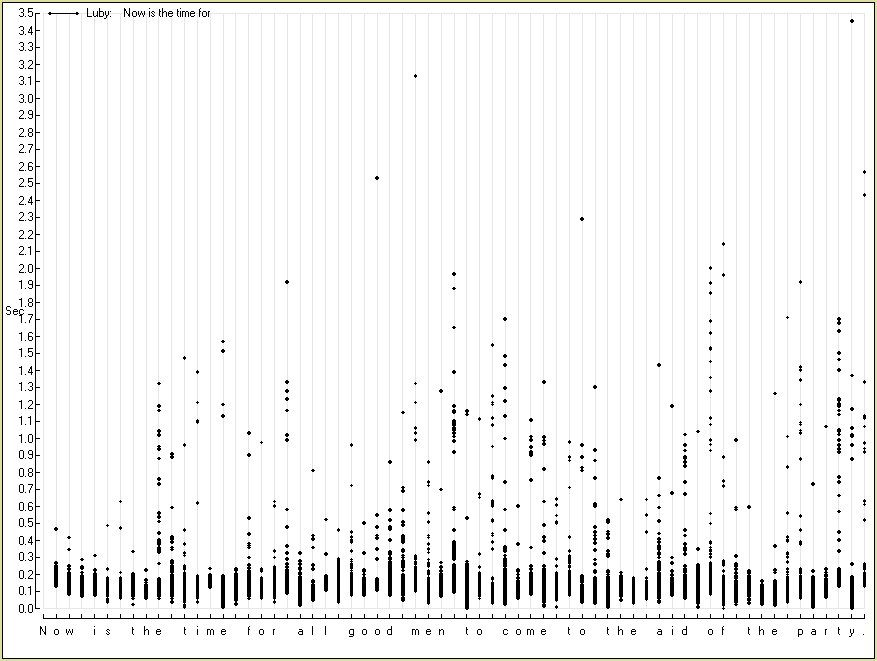
NOTE ADDED 10-APR-2005. The original computer programs have not been kept alive, and are possibly lost. As I recall, results improved considerably upon working with medians rather than means. As a median is a 50th percentile, probably the question arose of whether alternative percentiles might give even better results, but no recollection remains that they did. A profitable approach for the Stage 1 task above (relying on the sentence "Now is the time ...") would begin by computing a correlation coefficient between Variable A the single time entered at each position in the graph above by an unknown typist whose identity needed to be identified and Variable B the median time from many typings of the same sentence by a known typist. The same correlation would be computed for each of the several known typists whose data had been archived. Which archived typist was guessed to be responsible for the mystery sample would be pointed to by the highest correlation.
The pattern of times preceding (in the graph, appearing above) the "e" in "the" in "is the time" shows a point of difficulty — many times exceed 0.2 sec. The "e" in "the" in "to the aid", in contrast, is one of two points that are most trouble-free, a time exceedng 0.2 sec never being observed. The cause of this difference may lie mainly in antecedent events — that typing "is the" makes the "e" hard to type, whereas typing "to the" makes the "e" easy to type. Alternatively, the cause may lie mainly in the typist's anticipation of future characters that need to be typed, such that typing "the time" makes that "e" hard to type, whereas typing "the aid" makes that "e" easy to type. As the nearest past event that could make a difference is four characters back, whereas the nearest future event whose anticipation could make a difference is only two characters forward, a plausible hypothesis is that it is the anticipated future events that are more responsible for the difference in difficulty.
The only other character whose typing was never preceded by a time exceeding 0.2 sec, by the way, is the "h" in "of the party". That the other two instances of "the" did not produce quite such fast letters "h" again suggests that constraints extend beyond the two preceding characters (which are always "_t") and the two following characters (which are always "e_").
Similar conclusions follow from a comparison of the typing of other repeated sequences. The times preceding each of the two characters in the word "to", for example, differing radically depending on whether they were typed in the context "men to come" or "come to the".
It becomes apparent that typing behavior is rich enough to absorb a lifetime of study, a degree of study which may be encouraged by the computer and the Internet having made typing an increasingly prevalent component of communication.
HOME
|